
L’intelligence artificielle (IA) évolue à une vitesse fulgurante, et parmi les avancées les plus prometteuses, on trouve les Vision-Language Models (VLM). Ces modèles, qui combinent traitement de la vision par ordinateur et compréhension du langage naturel. Mais qu’est-ce qu’un VLM, comment fonctionne-t-il, et pourquoi suscite-t-il autant d’intérêt ?
Qu’est-ce qu’un Vision-Language Model (VLM) ?
Un Vision-Language Model est une architecture d’intelligence artificielle capable de traiter simultanément des données visuelles (images, vidéos) et des données textuelles (descriptions, questions, légendes). Contrairement aux IA traditionnelles qui se spécialisent dans un seul domaine (comme la vision par ordinateur ou le traitement du langage naturel), les VLM sont multimodaux, ce qui signifie qu’ils peuvent comprendre et interagir avec des informations provenant de plusieurs types de médias.
Par exemple, un VLM peut :
- Décrire le contenu d’une image en langage naturel.
- Répondre à des questions sur une photo ou une vidéo.
- Associer une légende pertinente à une image.
L’un des modèles emblématiques dans ce domaine est CLIP (Contrastive Language–Image Pretraining), développé par OpenAI, qui associe textes et images en identifiant les correspondances entre eux.
Comment fonctionnent les VLM ?
Les VLM reposent sur des architectures de type réseau de neurones, et plus précisément sur des variantes des modèles de transformateurs. Ces modèles, largement adoptés dans le traitement du langage naturel (comme GPT), ont été adaptés pour intégrer des flux d’informations visuelles.
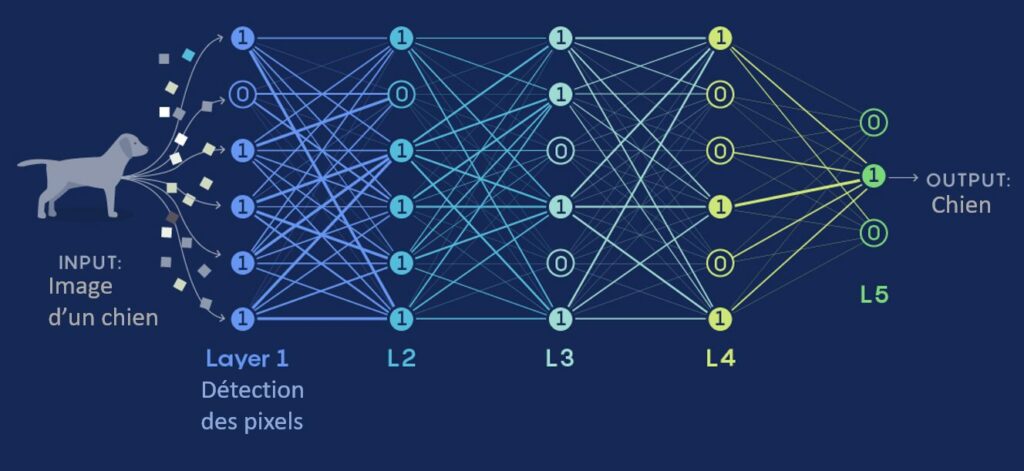
Étapes de fonctionnement :
- Prétraitement des données :
- Les images sont converties en représentations numériques à l’aide de réseaux neuronaux convolutionnels ou de variantes comme ViT (Vision Transformer).
- Les textes sont encodés grâce à des modèles de langage comme BERT ou GPT.
- Apprentissage des relations multimodales : Les modèles sont entraînés à comprendre la relation entre images et textes en utilisant des ensembles de données massifs. Par exemple, ils apprennent que l’image d’un chat correspond généralement au mot “chat”.
- Fine-tuning : Une fois pré entraîné, le modèle peut être affiné pour des tâches spécifiques, comme la détection d’objets, la génération de descriptions d’images, ou encore des applications interactives comme le Visual Question Answering (VQA).
À quoi servent les VLM ?
1. Accessibilité :
Les VLM peuvent aider les personnes malvoyantes en décrivant leur environnement ou le contenu visuel via des interfaces vocales.
2. Marketing et e-commerce :
Ils permettent de générer des descriptions automatiques pour les produits, ou de répondre aux questions des clients à partir d’une image du produit.
3. Santé :
Dans le domaine médical, un VLM peut analyser des images radiologiques et fournir des rapports préliminaires en langage naturel, accélérant ainsi les diagnostics.
4. Éducation :
Ces modèles peuvent être utilisés pour rendre l’apprentissage plus interactif, par exemple en permettant aux étudiants de poser des questions sur des schémas, des cartes ou des graphiques.
5. Automatisation industrielle :
Les entreprises peuvent utiliser des VLM pour analyser les flux vidéo dans les usines, détecter des anomalies, et générer des rapports en temps réel.
Les applications en entreprise
Analyse des réseaux sociaux :
Les entreprises peuvent exploiter les VLM pour analyser des images postées sur les réseaux sociaux, détecter des tendances visuelles, et comprendre le contexte linguistique des publications associées.
Recherche visuelle intelligente :
Les VLM permettent de chercher des images ou des vidéos dans de vastes bases de données en utilisant des descriptions textuelles. Par exemple, un moteur de recherche interne d’entreprise pourrait répondre à des requêtes comme “montrer les photos prises lors de la conférence de 2023”.
Création de contenu :
Ils simplifient la génération de contenu multimédia, en associant du texte à des visuels pertinents de manière automatique.
Conclusion
Les Vision-Language Models incarnent une nouvelle ère de l’IA où les frontières entre vision et langage s’effacent. En combinant ces deux domaines, ils révolutionnent notre façon d’interagir avec la technologie, que ce soit dans notre vie quotidienne ou en entreprise. Les perspectives d’évolution sont vastes, et il est clair que les VLM joueront un rôle central dans l’avenir de l’intelligence artificielle.
Alors que les entreprises s’efforcent d’intégrer ces technologies dans leurs stratégies, une chose est certaine : les VLM ne font que commencer à révéler leur potentiel. Restez à l’affût, car l’innovation dans ce domaine ne fait que commencer !